Validation: Assuring Data Integrity
Holochain DNAs can specify validation rules for DHT operations. This empowers agents to check the integrity of the data they see. When called upon to validate data, it allows them to identify corrupt peers, author a warrant against them as proof of their actions, and take personal defensive action against them.
What you’ll learn
- Why validation matters
- How complex validations can be sped up
- How validation rules are defined
- When validation happens
- What validation rules can be used for
- What makes a good validation rule
- System validation and validation-like things
Why it matters
Data validation rules are the core of a Holochain app. They deserve the bulk of your attention while you’re writing your DNA.

Validation: the beating heart of Holochain
Let’s review what we’ve covered so far.
- Holochain is a framework for building apps that let peers directly share data without needing the protective oversight of a central server.
- Holochain’s two pillars of integrity are intrinsic data validity and peer witnessing. The first defines what correct data looks like, while the second uses the strength of many eyes to rapidly detect corruption and reduce the overall burden of validation.
- Each type of app entry and link can contain any sort of binary data whose correctness is determined by validation rules written into the application.
- Peer validators use those rules to analyze entries, flag bad actors, and trigger personal defensive action such as blocking the corrupt agent.
Holochain is the engine that allows peers to move data around, validate it, and take action based on validation results. Your DNA is mainly a collection of functions for creating, accessing, and validating data. The design of these functions is critical to the success of your app because they define the membranes of safety between a participant and the stuff she receives from others via the DHT. Her running DNA — her cell — prevents her from creating invalid data and defends her from the consequences of other people’s invalid data. Well-designed validation rules protect everyone, while buggy validation rules leave them vulnerable.
‘Remembering’ validation results
Some entries can be computationally expensive to validate. In a currency app, for example, the validity of a transaction depends on the account balances of both transacting parties, which is the sum of all their prior transactions. The validity of each of those transactions depends on the account balance at the time, plus the validity of the account balance of the people they transacted with, and so on and so on. The data is deeply interconnected, a large graph of many small actions that all have to be checked for validity. But you don’t want to wait while the coffee shop’s payment terminal fetches half the town’s economic history when you’re just trying to buy a coffee and get to work.
The DHT offers a shortcut — it remembers the validation results of existing entries. You can ask the validation authorities for the parties’ previous transactions if they detected any problems. You can assume that they have done the same thing for the transaction prior to those, and so on. As long as you trust a decent number of your peers to be playing by the rules, the validation result attached to the most recent entry ‘proves’ the validity of all the entries before it.
The result of a validation, if it was able to complete, is stored. If validation failed, the validator produces a warrant which contains proof of the invalid action. If a participant asks an authority for a piece of data that happens to be invalid, the authority can return the warrant in place of the actual data.
While this works for finding the validity of one particular entry or action, a participant might have a reason to find out if another participant has ever produced any invalid data. Warrants are sent to the agent activity authorities, peers who have taken responsibility for data stored at the author’s public key. Holochain allows agents to consult these agent activity authorities for that peer and get all warrants at once.
How validation rules are defined
A validation rule is simply a callback function in an integrity zome that takes an operation, analyzes it, and returns a validation result. You’ll remember that an operation encapsulates the details of an action, so this function is validating whether the action’s author should have performed the action. The function has access to the whole DHT, so it can also base its result on context such as the author’s history or any data that the action may reference.
The validation function should cover all the operations produced by the act of creating, updating, or deleting entries and links of those types.
Non-determinism in validation functions
Entries and action can be retrieved by hash, as can entire sequences of a source chain. But collections such as links on a base or full agent activity reports can’t be retrieved, because they change over time and would lead to non-determinism in validation results. This would cause different validation authorities to give different answers, leading to disagreement on the validity of an operation.
Other sources of non-determinism, such as conductor host API functions that retrieve the time, read the cell owner’s own state, generate a random number, or call a zome function in another cell, are disallowed for the same reason.
Once it’s done its work, the validation function can return one of three values:
- Valid,
- Invalid, with an error message,
- Unresolved dependencies, with a list of the addresses of dependencies that it couldn’t retrieve from the DHT. (If the conductor fails to retrieve data, it’ll short-circuit execution of the validation function, return this value, and schedule the validation for retry later.)
All operations on CRUD actions whose entry or link types are defined in an integrity zome share a single validation function within that zome. Within this function, you can use branching logic to handle different operation types on different entry or link types.
System actions like membrane proof or capability grants result in operations that are validated by all integrity zomes. That’s because they have no entry or link type associated with them, so they can’t be defined in or routed to a specific integrity zome.
The lifecycle(s) of a validation
Validation functions are called in two different scenarios, each with different consequences:
- When an agent first authors a record and attempts to produce DHT operations from it, and
- When an authority receives an operation for validation.
We’ll carry on with the DHT illustrations from chapter 4 to show what happens when data is written, but let’s add a simple validation rule: there’s a word entry type that must be a string, but the string can’t contain spaces.
Authoring
When you commit a record, your conductor is responsible for making sure you’re playing by the rules. This protects you from publishing any invalid data that could make you look like a bad actor.
Valid entry
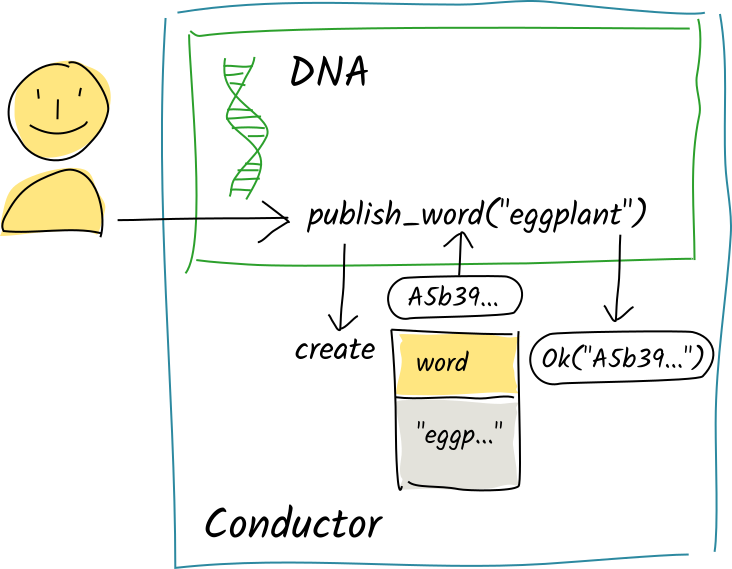
Alice calls the publish_word zome function with the string "eggplant". The function commits that word to her source chain. The conductor ‘stages’ the commit in the function’s ‘scratch space’, an in-memory store that captures pending changes, and returns the creation action’s record hash to the publish_word function. The function continues executing and passes a return value back to the conductor, which holds onto it for now.
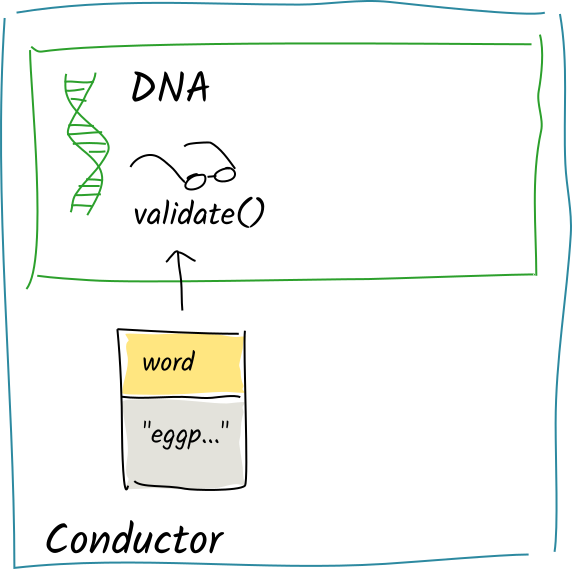
After the function has finished, Alice’s conductor converts this record into DHT operations, looks up the integrity zome that defines the word entry type, and calls that zome’s validation function on each of the operations.
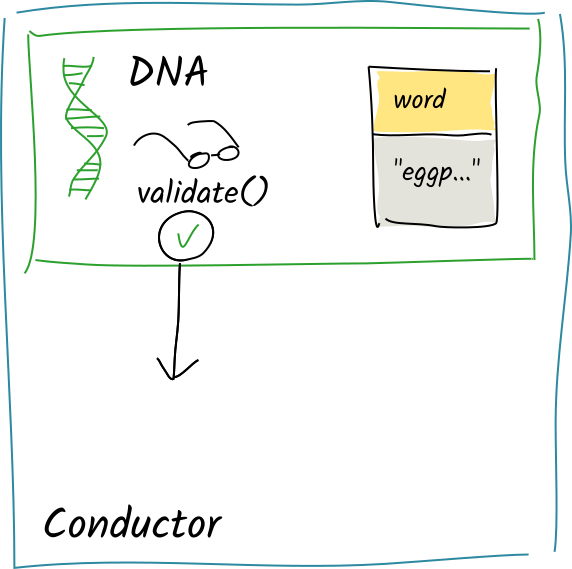
The validation function simply checks that the entry data contained in the action is only one word long, returning Valid.
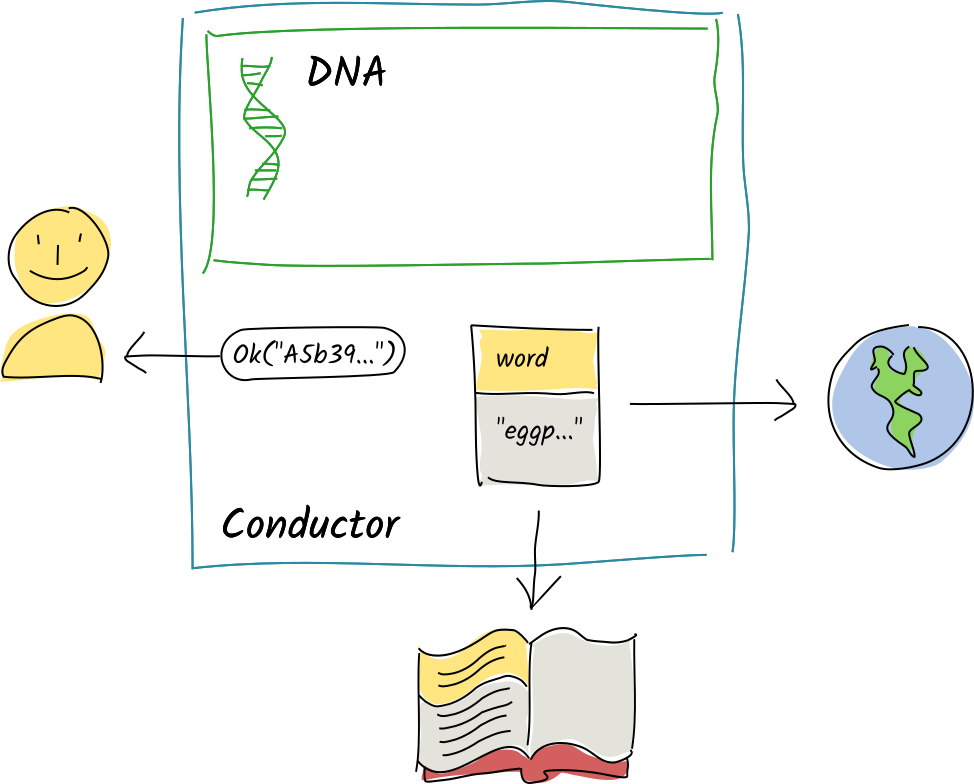
Her conductor flushes the scratch space, which contains the one action, to her source chain. Then it passes the publish_word function’s return value back to the client. Meanwhile, the operations are sent to the appropriate DHT authorities for validation and integration into their shards.
Invalid entry
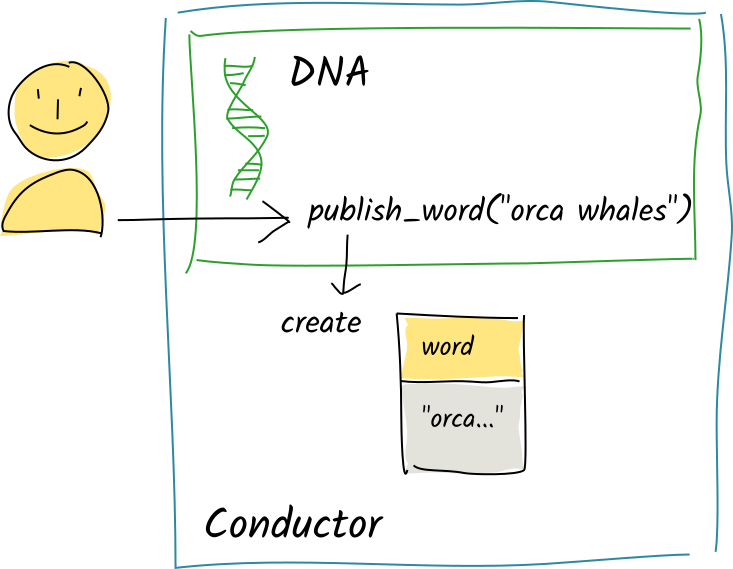
Alice calls the same zome function with the string "orca whales". Again, the function calls create_entry and the commit is staged to the scratch space.
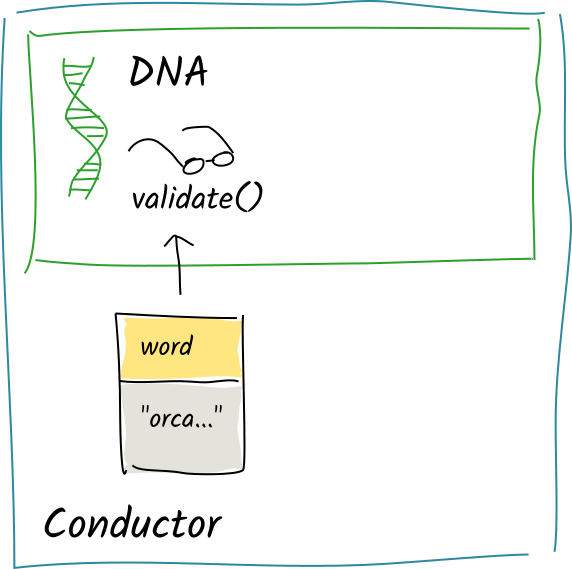
Again, the conductor converts the committed action into operations and calls the validation function on each of them.
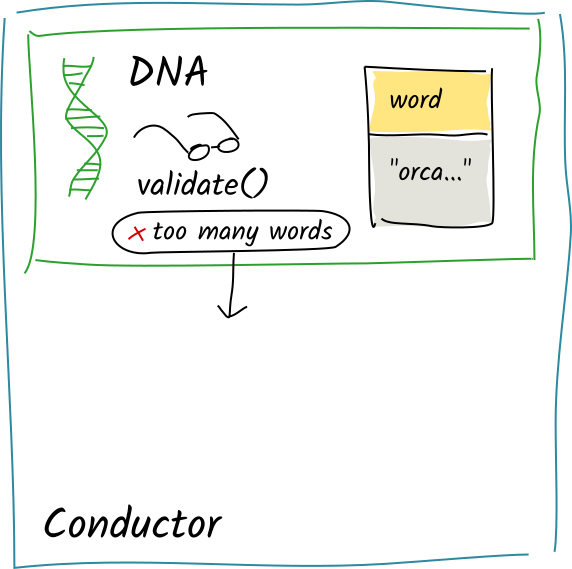
This time, the validation function sees two words. It returns Invalid("too many words").
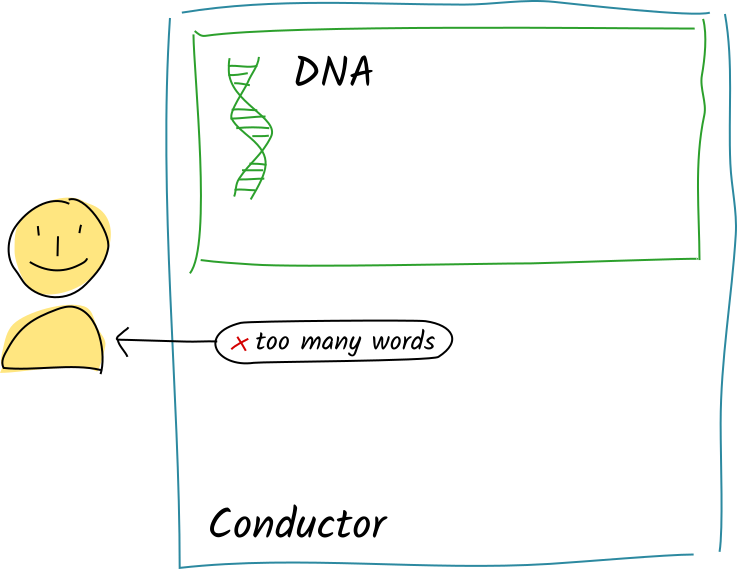
Instead of committing the entry, the conductor passes this error message back to the client instead of whatever the publish_word function’s return value was.
You can see that author-side validation is similar to how data validation works in a traditional client/server app: if something is wrong, the validation logic sends an error message back to the application logic, which can handle it as it sees fit (for example, parsing the error and asking the user to fix the invalid fields).
Peer validation
When an authority receives an entry for validation, the flow is different. The authority doesn’t just assume that Alice has already validated the data; she could easily have hacked her conductor to bypass validation rules. It’s the authority’s duty and right to treat every piece of data as suspect until they can personally verify it. Fortunately, they have their own copy of the validation rules.
Here are the two scenarios above from the perspective of a DHT authority.
Valid entry

Diana and Fred are authorities for the address E, so Alice publishes a copy of a store-entry operation that stores the "eggplant" entry at that address.
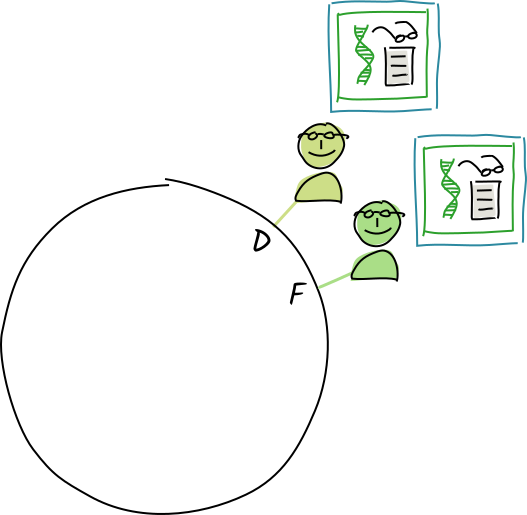
Their conductors call the appropriate validation function.

The operation is valid, so they store the entry and action in their personal DHT stores.

They both send a validation receipt back to Alice. Later on, they share the DHT operation with their neighbors for resilience.
Multiple operations for each action
You may remember from our exploration of the DHT that the ‘store entry’ operation is only one of three produced by the action that Alice committed to her chain. The ‘store record’ and ‘register agent activity’ operations are validated by other authorities, and the validation function may contain slightly different logic for each of them based on the context they have locally — for instance, the ‘register agent activity’ authority may not care about the number of words in the entry, but may check the author’s source chain (which is stored locally for these authorities but not for others) contains a permission to add new words to the DHT. Ultimately, all authorities can retrieve all record data for an operation, along with all source chain data preceding that record, and perform validation but it may make sense to distribute the work in ways that are appropriate for each operation.
Invalid entry
Let’s say Alice has taken off her guard rails — she’s hacked her Holochain software to bypass the validation rules.

Norman and Rosie receive a copy of Alice’s ‘store entry’ operation for "orca whales".
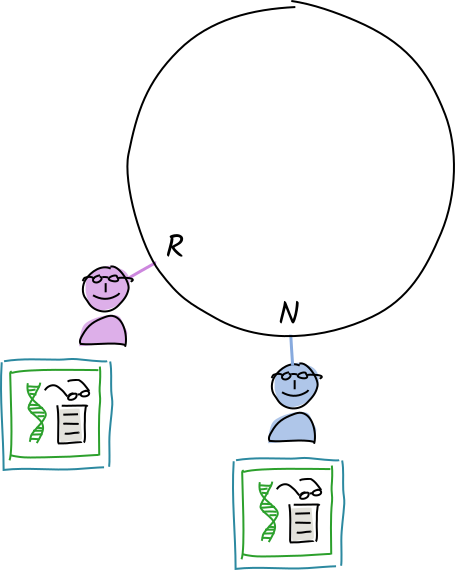
Their conductors call the validation function.
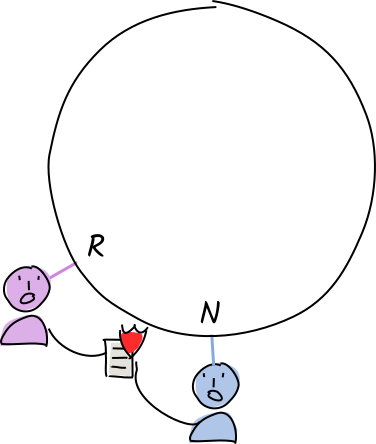
The operation is invalid. They create and sign warrants (a claim that the operation is invalid).
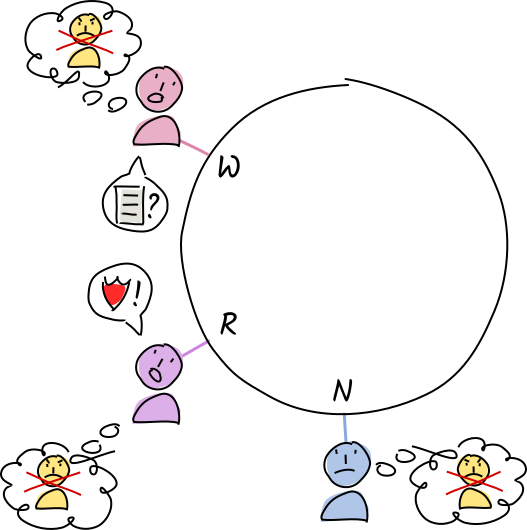
Norman and Rosie add Alice to their permanent block lists. When anyone asks for the data at the entry’s address, they return the warrant instead.

Norman and Rosie send a copy of their warrant to Alice’s neighbors, her agent activity authorities. Whenever anyone checks Alice’s status, they get a copy of this warrant and add her to their block lists too.

Eventually, everyone knows that Alice is a ‘bad actor’ who has hacked her app. They all ignore her whenever she tries to talk to them, which effectively ejects her from the DHT.
What happens when an agent encounters a warrant?
When an agent receives a warrant, the first step is to check that the warrant is legitimate by trying to fetch and validate the warranted data themselves. If it’s valid, they add the warranted agent to their network block list, stopping all incoming and outgoing communications with them. If it’s invalid, they block the malicious warrant issuer.
Use cases for validation
The purpose of validation is to empower a group of individuals to hold one another accountable to a shared set of rules. This is a pretty abstract claim, so let’s break it down into a few categories. With validation rules, you can define things like:
- Access membranes — validation rules on the membrane proof govern who’s allowed to join a DNA’s network and see its data.
- The shape of valid data — validation rules on entry and link types that hold data can check for properly structured data, upper/lower bounds on numbers, string lengths, non-empty fields, or correctly formatted content.
- Rules of the game — validation rules on connected graph data, including the history in the author’s source chain and entries countersigned with others, can make sure chess moves, transactions, property transfers, and votes are legitimate.
- Privileges — validation rules that focus on the type of action (create, update, or remove) can define who gets to do what.
- Rate limiting — each CRUD action has a weight field that, along with the timestamp, entry/link type, and source chain history, can be used to create a validation rule that rejects actions if they’re costly and are written too frequently.
Guidelines for writing validation rules
It’s already been mentioned, but it bears repeating: validation functions are deterministic and pure, returning a clear yes/no answer for a given operation no matter who executes them. The only exception is when data upon which the validation depends can’t be retrieved, in which case the result is inconclusive and the validation will be tried again later.
If an action depends on other DHT data for its validity, a reference to the dependencies must be able to be constructed from the action data alone. The action has a built-in reference to the previous source chain action, and all other dependencies can be referenced explicitly by address or by something that can be used to reliably construct an address (such as an anchor).
A record contains an action taken by an agent, with a reference to their local history, so the validation function’s job is to decide whether they ought to have taken the action at that point in time. Action timestamps come from the author’s local clock and can be forged. This makes it challenging to implement validation for cases where a privilege may be revoked. Useful patterns for addressing this include getting a signed timestamp from a trusted third party, or getting a signed proof from the administrator that the privilege is still active.
If an agent is committing a record to their source chain that depends on DHT data, it’s their job to make sure those references exist at commit time and explicitly reference them. The validation function doesn’t need to revalidate those dependencies, though; Holochain will use its own heuristics to determine the trustworthiness of other validators’ claims when it retrieves them. This lets you write ‘inductive’ validation rules — algorithms that only check an operation’s validity in the context of its immediate dependencies only, assuming that, if the agents holding the dependencies don’t report any problems, they’ve applied the same inductive reasoning. Inductive validation is especially useful for data that has a large graph of dependencies behind it.
Soft things which normally require human discretion, like content moderation and code-of-conduct enforcement, are also challenging to encode unambiguously.
System-level validation and validation-like things
Hashes, signatures, and chain continuity
At the system level, Holochain checks hashes and author signatures. If either of them don’t match the data being validated, the operation is rejected. Agent activity authorities also check that source chain actions are integrated in sequence, and form a non-broken chain with timestamps and sequence indices that don’t go backwards.
Source chain forks
We discussed a situation in which an agent attempts to create two parallel histories, in the section on the DHT. System-level validation considers this ‘fork’ a validation error, and applies it to the whole chain and its author rather than the two operations that caused the fork. Authorities who haven’t yet seen the fork may temporarily disagree with those who have seen it, but eventually all authorities will agree once they receive the same set of operations.
Source chain forks can happen accidentally
We recognize that some source chain forks are accidental, for example when an agent backs up their device, commits and publishes an action, then loses their device and has to recover from a backup. The next action they publish will create a fork. We plan to address this scenario in a way that balances security and usability.
Genesis self-check
A genesis self-check function can be defined in your integrity zomes. Its job is to ‘pre-validate’ an agent’s membrane proof before she joins a network, to prevent her from accidentally committing a membrane proof that would forever bar her from joining the network.
This function exists because it may require DHT access to fully check the validity of a membrane proof, but the newcomer isn’t yet part of the network when they attempt to publish their membrane proof action. So this function verifies as much as it can without network access.
If the self-check fails, the cell fails to be created and the rest of the cells in the hApp are disabled. Then an error is passed back to the system that’s trying to install the app, which should then show an error message to the user.
Application-level blocking
Future feature
This section describes an unimplemented feature.
Some reasons for ejecting an agent from a network simply shouldn’t be encoded in a validation function, either because they require human discretion, would need too much processing power to validate properly, or aren’t the result of an invalid action. These can include things like an employee’s departure from a company, behavior that violates a community’s code of conduct, or disturbing images and videos. These application-level blocks can also be temporary, so they can be lifted if someone is to be reinstated into a network. Holochain’s host SDK provides block and unblock functions for these purposes, and you can use these functions to build ‘soft’ immune responses.
Key takeaways
- Validation rules are the most important part of a Holochain DNA, as they define the core domain logic that comprises the ‘rules of the game’.
- Validation supports intrinsic data integrity, which upholds the security of a Holochain app.
- Validation rules can be written for an agent’s entry into an application, the shape and content of data, rules for interaction, write permissions, and write throttling.
- An author validates their own entries before committing them to their source chain or publishing them to the DHT.
- Peers in the DHT subject all public data to validation before storing. This validation uses the same rules that the author used at the time of commit.
- If all data upon which a validation depends can be retrieved, the result of a validation function is a clear yes/no result. It proves whether the author has hacked their software to produce invalid entries.
- If some data dependencies can’t be retrieved from the DHT, the conductor will fail with an ‘unresolved dependencies’ error and try again later.
- If the validity of an operation depends on existing DHT data, a validating agent can generally trust in the existing validation results on those dependencies instead of having to revalidate them.
- Validation functions are deterministic and pure, and should also cover all possible input values.
- When an operation is found to be invalid, the validator creates a warrant, which attests that the author is writing corrupt data.
- Warrants are published to agent activity authorities and returned in place of invalid data when it’s requested.
- When an agent discovers a warrant, they use it as grounds for blocking communication with the warranted agent.
- System-level validation checks for source chain forks.
- Genesis self-checking occurs before an agent joins a network, catching basic errors that don’t require dependencies to by fetched.
- Application-level blocking and unblocking can be used to provide an immune-like response when there are non-deterministic or non-adversarial reasons for blocking an agent.
Learn more
- Wikipedia: Deterministic algorithm
- Wikipedia: Pure function
- Wikipedia: Partial function (contains a complementary definition of a total function)
- Wikipedia: Monotonicity of entailment, a useful principle for writing validation functions that update entries without invalidating old ones
- Wikipedia: Byzantine fault, describing the nature of failures among nodes in a distributed computing system
