Zero to Built: Creating a Forum App
In this tutorial you’ll use Holochain’s scaffolding tool to generate back-end and UI code for all the data types and collections needed to build a functioning forum app. It assumes that you’ve already installed the Holochain development environment, set up a folder for working on Holochain applications, and scaffolded a Hello World application.
First, navigate back to the folder where you want to keep your Holochain applications. If you followed our suggestion, you can get back to it by typing:
cd ~/Holochain
Next up, we’ll walk you through creating a forum application from scratch using Holochain’s scaffolding tool, step-by-step. This forum application will enable participants to share text-based posts and to comment on those posts.
Each post will have a title and content, and authors will be able to edit — or update — their posts. However, they won’t be able to delete them.
Each comment will be a reply to a particular post, will be limited in length to 140 characters, and will be able to be deleted but not updated.
Validation tutorial coming soon
A future update to this guide will implement the above constraints as validation rules. For now, we’ll just scaffold enough code to get a working UI. Check back soon to get the whole tutorial!
We’ll create a couple of other things along the way that will enable people to find these posts and comments, but we’ll cover those things when we get there.
The good news is that the Holochain scaffolding tool will do a lot of the heavy lifting in terms of generating folders, files, and boilerplate code. It will walk you through each step in the hApp generation process. In fact, the scaffolding tool does so much of the work for you that many people have commented that 90% or more of the time spent writing a Holochain app is focused on building out the front-end user interface and experience.
First, let’s use the scaffolding tool to generate the basic folders and files for our hApp.
1. Start scaffolding
To start, run the following command in your terminal:
nix run "github:/holochain/holonix?ref=main-0.6#hc-scaffold" -- web-app
Backing out of a mistake
A quick note: if, while scaffolding some part of your hApp, you realize you’ve made a mistake (a typo or wrong selection for instance), as long as you haven’t finished scaffolding that portion, you can stop the current step by using Ctrl+C on Linux or Command+C on macOS.
If you’re experienced with Git, the scaffolding tool will initialize a Git repo in your project folder. That means you’ll be able to use git commands to take snapshots of your work and back out any changes you’ve already completed.
2. Select user interface framework
You’ll then be prompted to choose a user interface (UI) framework for your front end. For this example, use the arrow keys to choose Svelte and press Enter.
? Choose UI framework: (Use arrow-keys. Return to submit) ›
lit
❯ svelte
vue
react
vanilla
headless (no ui)
3. Choose a name for your app
You’ll then be asked to give your app a name.
? App name (no whitespaces):
Enter the name of your forum application using snake_case. Enter:
my_forum_app
4. Set up Holonix development environment and JS package manager
Next, you’ll be asked if you want to set up the Holonix development environment for the project.
? Do you want to set up the holonix development environment for this project? ›
❯ Yes (recommended)
No
This allows you to enter a shell that has all the right tools and libraries for the version of Holochain that your code was generated for.
Choose Yes (recommended) and press Enter.
5. Scaffold a DNA
The next step asks you whether you want to scaffold an initial DNA. A DNA is where you will put the code that defines the rules of your application. Simple applications like this one only need one DNA, so say yes:
? Do you want to scaffold an initial DNA? (y/n) ›
❯ Yes
No
You should then see:
? DNA name (snake_case):
Erase the default (which is just the hApp name) and type in:
forum
DNAs: Context and Background
Why do we use the term DNA?
With Holochain, we’re trying to enable people to choose to participate in coherent social coordination, or interact meaningfully with each other online without needing a central authority to define the rules and keep everyone safe. To do that, we are borrowing some patterns from how biological organisms are able to coordinate coherently even at scales that social organizations such as companies or nations have come nowhere close to. In living creatures like humans, dolphins, redwood trees, and coral reefs, many of the cells in the body of an organism (trillions of the cells in a human body, for instance) are each running a (roughly) identical copy of a rule set in the form of DNA.
This enables many different independent parts (cells) to build relatively consistent superstructures (a body, for instance), move resources, identify and eliminate infections, and more — all without centralized command and control. There is no “CEO” cell in the body telling everybody else what to do. It’s a bunch of independent actors (cells) playing by a consistent set of rules (the DNA) coordinating in effective and resilient ways.
A cell in the muscle of your bicep finds itself in a particular context, surrounded by certain resources and conditions. Based on those signals, that cell behaves in particular ways, running relevant portions of the larger shared instruction set (DNA) and transforming resources in ways that make sense for a bicep muscle cell. A different cell in your blood, perhaps facing a context where there is a bacterial infection, will face a different set of circumstances and consequently will make use of other parts of the shared instruction set to guide how it behaves. In other words, many biological organisms make use of this pattern where all participants run the same rule set, but each in its own context, and that unlocks a powerful capacity for coherent coordination.
Holochain borrows this pattern that we see in biological coordination to try to enable similarly coherent social coordination. However, our focus is on enabling participants to “opt into” such coherent social coordination. We believe that this pattern of being able to choose which games you want to play — and being able to leave them or adapt them as experience suggests — is critical to enabling individual and collective adaptive capacity. We believe that it may enable a fundamental shift in the ability of individuals and communities to sense and respond to the situations that they face.
To put it another way: if a group of us can all agree to the rules of a game, then together we can play that game.
All of us opting in to those rules — and helping to enforce them — enables us to play that game together, whether it is a game of chess, chat, a forum app, or something much richer.
DNA as boundary of network
The network of participants that are running a DNA engage in “peer witnessing” of each other’s actions in that network. A (deterministically random) set of peers are responsible for validating, storing, and serving each particular piece of shared content. In other words, the users of a particular hApp agree to a set of rules and then work together collectively to enforce those rules and to store and serve content (state changes) that do not violate those rules.
Every hApp needs to include at least one DNA. Moreover, as indicated above, it is at the DNA level (note: not the higher application level) where participants will form a network of peers to validate, store, and serve content in accordance with the rules defined in that DNA. This happens in the background as the application runs on each participant’s machine.
There are some powerful consequences to this architectural choice — including freedom to have your application look and feel the way you want, or to combine multiple DNAs together in ways that work for you without having to get everyone else to agree to do the same — but we’ll save those details for later.
So if we have multiple DNAs in our hApp…
…then we are participating in multiple networks, with each network of peers that are participating in a particular DNA also helping maintain the shared database for that DNA, enforcing its rules while validating, storing, and serving content. Each network acts as a ‘social organism’ in cooperation with other networks in the hApp.
This is similar to the way in which multiple DNA communities coexist in biological organisms. In fact, there are more cells in a human body that contain other DNA (like bacteria and other microorganisms) than cells that contain our DNA. This indicates that we are an ecology of coherent communities that are interacting with — and evolving alongside — one another.
When it comes to hApps, this lets us play coherent games with one another at the DNA level, while also participating in adjacent coherent games with others as well. That means that applications are not one-size-fits-all. You can choose to combine different bits of functionality in interesting and novel ways.
6. Scaffold some zomes
DNAs are comprised of code modules, which we call zomes (short for chromosomes). Zomes are modules that typically focus on enabling some small unit of functionality. Building with this sort of modular pattern provides a number of advantages, including the ability to reuse a module in more than one DNA to provide similar functionality in a different context. For instance, the profiles zome is one that many apps make use of as a complete component to manage a user profile. For the forum DNA, you’ll be creating two zomes: posts and posts_integrity.
Now that you’ve scaffolded a DNA, you should see this prompt:
? Do you want to scaffold an initial coordinator/integrity zome pair for your DNA? (y/n) ›
❯ Yes
No
Say yes to it, and then you should then see:
? Enter coordinator zome name (snake_case):
(The integrity zome will automatically be named '{name of coordinator zome}_integrity')
Erase what’s there and give it the name posts. Then it’ll ask you to confirm the names of the two new folders it’ll generate; press y for both.
✔ Scaffold integrity zome in folder "dnas/forum/zomes/integrity/"? (y/n) · yes
? Scaffold coordinator zome in "dnas/forum/zomes/coordinator/"? (y/n) · yes
Now the skeleton structure of your forum project has been scaffolded. You’ll see some instructions for next steps:
Coordinator/integrity zome pair scaffolded.
This skeleton provides the basic structure for your Holochain web application.
The UI is currently empty; you will need to import necessary components into the top-level app component to populate it.
Here's how you can get started with developing your application:
- Set up your development environment:
cd my_forum_app
nix develop
npm install
- Scaffold an entry-type for your hApp:
hc scaffold entry-type
- Then, at any point in time you can start your application with:
npm run start
Integrity zomes and coordinator zomes
Integrity zomes
An integrity zome, as the name suggests, is responsible for maintaining the data integrity of a Holochain application. It sets the rules and ensures that any data writes occurring within the application are consistent with those rules. In other words, it’s responsible for ensuring that data is correct, complete, and trustworthy. Integrity zomes help maintain a secure and reliable distributed peer-to-peer network by enforcing the validation rules defined by the application developer — in this case, you!
Coordinator zomes
On the other hand, a coordinator zome contains the code that actually commits data, retrieves it, or sends and receives messages between peers or between other portions of the application on a user’s own device (between the back end and the UI, for instance). A coordinator zome is where you define the API for your DNA, through which the network of peers and their data is made accessible to the user.
Multiple zomes per DNA
As you learned earlier, a DNA can have multiple integrity and coordinator zomes. Each integrity zome contributes to the full set of different types of valid data that can be written, while each coordinator zome contributes to the DNA’s functionality that you expose through its API. In order to write data of a certain type, a coordinator zome needs to specify a dependency on the integrity zome that defines that data type. A coordinator zome can also depend on multiple integrity zomes.
Why two types?
They are separated from one another so we can update coordinator zomes without having to update the integrity zomes. This is important, because changes made to an integrity zome result in a change of the rule set, which results in an entirely new network. This is because the integrity code is what defines the ‘rules of the game’ for a group of participants. If you changed the code of an integrity zome, Holochain would consider it a new ‘game’ and you would find yourself suddenly in a new and different network from the other folks who haven’t yet changed their integrity zome — and we want to minimize those sorts of forks to situations where they are needed (like when a community decides they want to play by different rules, for instance changing the maximum length of comments from 140 characters to 280 characters).
At the same time, a community will want to be able to improve the ways in which things are done in a Holochain app. This can take the form of adding new features or fixing bugs, and we also want people to also be able to take advantage of the latest features in Holochain. Separating integrity and coordination enables them to do that more easily, because:
- Holochain’s coordinator zome API receives frequent updates while the integrity zome API is fairly stable, and
- coordinator zomes can be added to or removed from a DNA at runtime without affecting the DNA’s hash.
Once that is all done, your hApp skeleton will have filled out a bit. Before you scaffold the next piece, it might be good to get a little context for how content is “spoken into being” when a participant publishes a post in a forum hApp. Expand and read the following section to learn more.
Source chains, actions, and entries
Source chain
Any time a participant in a hApp takes some action that creates or changes data, they do it by adding a record to a journal called a source chain. Each participant has their own source chain, a local, tamper-proof, and chronological store of the participant’s actions in that application.
This is one of the main differences between Holochain and other systems such as blockchains or centralized server-based applications. Instead of recording a “global” (community-wide) timeline of what actions have taken place, in Holochain actions are recorded on individual timelines. They can be thought of as both a change to the individual’s state and an attempt to change shared state.
One big advantage of this approach is that a single agent can be considered authoritative about the order in which they took actions. From their perspective, first they did A, then B, then C, etc. The fact that someone else didn’t get an update about these changes, and possibly received them in a different order, doesn’t matter. The order that the authoring agent took those actions will be captured in the actions themselves (thanks to each action referencing the previous one that they had taken, thus creating an ordered sequence — or chain — of actions).
Actions and entries
You’ll notice that we used the word “action” a lot. In fact, we call an item on the source chain an action. In Holochain applications, data is always “spoken into being” by an agent (a participant). Each action captures their act of adding, modifying, or removing data, rather than simply capturing the data itself.
There are a few different kinds of actions, but the most common one is Create, which creates an ‘entry’ — an arbitrary blob of bytes. Entries store most of the actual content created by a participant, such as the text of a post in our forum hApp. When someone creates a forum post, they’re recording an action to their source chain that reads something like: I am creating this forum post entry with the title “Intros” and the content “Where are you from and what is something you love about where you live?” and I would like my peers in the network to publicly store a record of this act along with the data itself. So while an action is useful for storing noun-like data like messages and images, it’s actually a verb, a record of an action that someone took to update their own state and possibly the shared state as well. That also makes it well-suited to verb-like data like document edits, game moves, and transactions.
Every action contains the ID of its author (actually a cryptographic public key), a timestamp, a pointer to the previous source chain record, and a pointer to the entry data, if there is any. In this way, actions provide historical context and provenance for the entries they operate on.
The pointer to the previous source chain record creates an unbroken history from the current record all the way back to the source chain’s starting point. This ‘genesis’ record contains the hash of the DNA, which serves as both the identifier for the specific set of validation rules that all following records should follow and the ID of the network that this source chain’s actions are participating in.
An action is cryptographically signed by its author and is immutable (can’t be changed or erased from either the source chain or the network’s data store) once written. This, along with the validation rules specified by the DNA hash in the genesis record, are examples of a concept we call “intrinsic data integrity”, in which data carries enough information about itself to be self-validating.
Just as with a centralized application, we aren’t just going to add this data into some database without checking it first. When a participant tries to write an action, Holochain first:
- ensures that the action being taken doesn’t violate the validation rules of the DNA,
- adds it as the next record to the source chain, and then
- tells the participant’s network peers about it so they can validate and store it, if it’s meant to be public.
The bits of shared information that all the peers in a network are holding are collectively called a distributed hash table, or DHT. We’ll explain more about the DHT later.
If you want to learn more, check out The Source Chain: A Personal Data Journal and The DHT: A Shared, Distributed Graph Database. You’ll also get to see it all in action in a later step, when you run your hApp for the first time.
7. Enter the dev environment
Now you’re ready to start working in your dev environment. Enter the hApp project folder:
cd my_forum_app
Just to get an overview of what’s been scaffolded for you, you can check the contents of that my_forum_app folder by typing:
ls
It should look like it has set up a similar set of folders and configuration files to those you saw in the “Hello World!” hApp.
Now, fire up the nix development shell, which makes all scaffolding tools and the Holochain binaries directly available from the command line, by entering:
nix develop
After a short while of installing packages, your terminal prompt should change:
[holonix:~/Holochain/my_forum_app]$
This lets you know you’re in the Holonix development shell. If you want to leave it at any time, you can type exit. This will take you back to your familiar shell without any of the special Holochain dependencies. When you want to re-enter it, navigate to the my_forum_app folder and type nix develop again.
To see what the nix shell has done for you, type:
holochain --version
You should see something like:
holochain 0.6.1-rc.7
If you were to type exit and try the same command, you’d probably get some sort of ‘command not found’ error!
Now that we’re in, let’s move on to installing the Node Package Manager (npm) dependencies with:
npm install
These dependencies are used by various tools and assets — the scaffolded tests, the UI, and various development activities like spawning apps for testing.
When that finishes, you should see some text that ends with something like:
added 371 packages, and audited 374 packages in 1m
37 packages are looking for funding
run 'npm fund' for details
found 0 vulnerabilities
If you see something like that, you’ve successfully downloaded the NPM dependencies for the UI and for building your app.
8. Scaffold entry types
An entry type is a fundamental building block used to define the structure and validation rules for data within a distributed application. Each entry type corresponds to a specific kind of data that can be stored, shared, and validated within the application.
Entry types and validation
An entry type is just a label, an identifier for a certain type of data that your DNA deals with. It serves as something to attach validation rules to in your integrity zome, and those rules are what give an entry type its meaning. They take the form of code in a function that gets called any time something is about to be stored, and because they’re just code, they can validate all sorts of things. Here are a few key examples:
Data structure: When you use the scaffolding tool to create an entry type, it generates a Rust struct that defines fields in your entry type, and it also generates code in the validation function that attempts to convert the raw bytes into an instance of that type. By providing a well-defined structure, this type ensures that data can be understood by the application. If it can’t be deserialized into the appropriate Rust structure, it’s not valid.
Constraints on data: Beyond simple fields, validation code can constrain the values in an entry — for instance, it can enforce a maximum number of characters in a text field or reject nonsensical calendar dates.
Privileges: Because it originates in a source chain, an entry comes with metadata about its author. This can be used to control who can create, edit, or delete an entry.
Context: Because an action is part of a chain of actions, it can be validated based on the agent’s history — for instance, to prevent currency transactions beyond a credit limit or disallow more than two comments per minute to discourage spam. An entry can also point to other actions and entries in the DHT upon which it depends, and their data can be used in its validation.
Your bare-bones forum needs two entry types: post and comment. You’ll define these in the posts integrity zome you just created in the previous step. The post entry type will define a title field and a content field. The comment entry type will define a content field and a reference to the post it should be attached to.
To do this, just follow the instructions that the scaffold suggested for adding new entry definitions to your zome.
Start with the post entry type by entering this command:
hc scaffold entry-type
You should then see:
✔ Entry type name (snake_case):
Enter the name:
post
You should then see:
Which fields should the entry contain?
? Field name: ›
The scaffolding tool is now prompting you to add fields to the post entry type.
Fields are the individual components or attributes within a Rust struct. They determine the specific pieces of information to be stored in an entry and their respective data types. The scaffolding tool supports a collection of native Rust types such as booleans, numbers, enums (a choice between several predetermined values), optional values, and vectors (lists of items of the same type), along with Holochain-specific types that refer to other pieces of data on the DHT.
For your post entry type, you’re going to add title and content fields. Enter the name of the first field:
title
Next, it asks you to choose a field type:
? Choose field type: ›
❯ String
bool
u32
i32
f32
Timestamp
ActionHash
EntryHash
DnaHash
ExternalHash
AgentPubKey
Enum
Option of...
Vector of...
Choose String and press Enter.
Press Y for the field to be visible in the UI, and select TextField as the widget to render this field. (A TextField is a single-line input field designed for capturing shorter pieces of text.)
When you see:
? Add another field to the entry?(y/n)
press Y.
Then enter the name content for this field’s name and choose String as its type. Press Y for the field to be visible in the UI, and select TextArea as the widget to render the field. (A TextArea is a multi-line input field that allows users to enter larger blocks of text. That’ll work better for forum posts.)
After adding the title and content fields, press N when asked if you want to add another field. Next, you should see:
Chosen fields:
title: String
content: String
? Do you want to proceed with the current entry type or restart from the beginning? ›
❯ Confirm
Modify
Restart
If the summary of your fields looks like this, press Enter to confirm that it’s correct. Next, you’ll see:
Which CRUD functions should be scaffolded (SPACE to select/unselect, ENTER to continue)?
✔ Update
✔ Delete
The scaffolding tool can add zome and UI functions for updating and deleting entries of this type. In this case, we want authors to be able to update posts, but not delete them, so use the arrow keys and the spacebar to ensure that Update has a check and Delete does not. It should look like this:
Which CRUD functions should be scaffolded (SPACE to select/unselect, ENTER to continue)?
✔ Update
Delete
Then press Enter.
At this point you should see:
? Should a link from the original entry be created when this entry is updated? ›
❯ Yes (more storage cost but better read performance, recommended)
No (less storage cost but worse read performance)
Select Yes by pressing Enter.
CRUD (create, read, update, delete)
Mutating immutable data and improving performance
In short, the above choice is about how changes get dealt with when a piece of content is updated.
Because all data in a Holochain application is immutable once it’s written, we don’t just go changing existing content, because that would break the integrity of the agent’s source chain as well as the data already in the DHT. So instead we add metadata to the original data, indicating that people should now look elsewhere for the data or consider it deleted. This is produced by Update and Delete source chain actions.
For an Update action, the original Create or Update action and its entry content on the DHT get a ReplacedBy pointer to the new Update action and its entry content.
When the scaffolding tool asks you whether to create a link from the original entry, though, it’s not talking about this pointer. Instead, it’s talking about an extra piece of metadata that points to the very newest entry in a chain of updates. If an entry were to get updated, and that update were updated, and this were repeated three more times, anyone trying to retrieve the entry would have to query the DHT six times before they finally found the newest revision. This extra link, which is not a built-in feature of updates, ‘jumps’ them past the entire chain of updates at the cost of a bit of extra storage. The scaffolding tool will generate all the extra code needed to write and read this metadata in its update and read functions. You can read more about links in the Core Concepts section on Links and Anchors.
For a Delete action, the original action and its entry content are simply marked as dead. In the cases of both updating and deleting, all original data is still accessible if the application needs it.
Resolving conflicts
Multiple participants can mark a single entry as updated or deleted at the same time. This might be surprising, but Holochain does this for two good reasons. First, it’s surprisingly difficult to decide which is the ‘correct’ version of a piece of data in a distributed system, because contributions may come from any peer at any time, even appearing unexpectedly long after they’ve been created. There are many strategies for resolving the conflicts that arise from this, which brings us to the second good reason: we don’t want to impose a specific conflict resolution strategy on you. Your application may not even consider parallel updates and deletes on a single entry to be a conflict at all.
CRUD functions
By default, the scaffolding tool generates a `create_<entry_type>’ function in your coordinator zome for an entry type because creating new data is a fundamental part of any application, and it reflects the core principle of Holochain’s agent-centric approach — the ability to make changes to your own application’s state.
Similarly, when a public entry is published, it becomes accessible to other agents in the network. Public entries are meant to be shared and discovered by others, so a `read_<entry_type>’ function is provided by default to ensure that agents can easily access and retrieve publicly shared entries. (The content of private entries, however, are not shared to the network.) For more info on entries, see: the Core Concepts sections on Source Chains and DHT.
Developers decide whether to let the scaffolding tool generate update_<entry_type> and delete_<entry_type> functions based on their specific application requirements. More details in the Core Concepts section on CRUD.
Next, you should see:
Entry type "post" scaffolded!
Add new collections for that entry type with:
hc scaffold collection
We’ll dive into collections in a moment, but first let’s create the comment entry type.
Again type:
hc scaffold entry-type
This time enter the name:
comment
for the entry type name.
Next, create a content field and select String as its type. Choose Y to create UI for it, then select the TextArea widget and press Enter. (Again, a TextArea is a multi-line input field that allows users to enter larger blocks of text. Perfect for a comment on a post.)
Press Y to add another field.
For this next field you’ll want to create a field that will help you associate each particular comment to the post that it’s commenting on. To do this, the next field in the comment entry type will store a reference to a post.
Enter post_hash as the field name, press Enter, and use the arrow keys to select ActionHash as the field type.
Hashes and other identifiers
There are two kinds of unique identifiers or ‘addresses’ in Holochain: hashes for data and public keys for agents.
A hash is a unique “digital fingerprint” for a piece of data, generated by running it through a mathematical function called a hash function. None of the original data is present in the hash, but even so, the hash is extremely unlikely to be identical to the hash of any other piece of data. If you change even one character of the entry’s content, the hash will be radically (and unpredictably) different.
Holochain uses a hash function called blake2b. You can play with an online blake2b hash generator to see how changing content a tiny bit alters the hash. Try hashing hi and then Hi and compare their hashes.
To ensure data integrity and facilitate efficient data retrieval, each piece of data is identified by its hash. This serves the following purposes:
- Uniqueness: The cryptographic hashing function ensures that the data has a unique hash value, which helps to differentiate it from other data on the network.
- Efficient lookup: The hash is used as a key (essentially an address) in the network’s storage system, the distributed hash table (DHT). When an agent wants to retrieve data, they simply search for it by hash, without needing to know what peer machine it’s stored on. In the background, Holochain reaches out simultaneously to multiple peers who are responsible for the hash based on an algorithm that matches peers to data based on the similarity of the hash to their agent IDs. This makes data lookup fast and resilient to unreliable peers or network conditions.
- Fair distribution: Because the participants in a network are responsible for validating and storing each other’s public data based on its hash, the randomness of the hashing function ensures that the responsibility for the entire data set is spread fairly evenly among everyone.
- Integrity verification:
Hiwill always generate the same hash no matter who runs it through the hashing function. So when data is retrieved by hash, its hash can be recalculated and compared with the original requested hash to ensure that a third party hasn’t tampered with the data. - Collusion resistance: The network peers who take responsibility for validating and storing an entry are chosen randomly based on the similarity of their agent IDs to the
EntryHash. It would take a huge amount of computing power to generate a hash that would fall under the responsibility of a colluding peer. And because Holochain can retrieve data from multiple peers, it’s more likely that the requestor can find one honest peer to report problems with a piece of bad data.
ActionHash
An action is identified by its ActionHash. Because an action contains information about its author, the time it was written, the action that preceded it, and the entry it operates on, no two action hashes will be the same — even for two Create actions that write the same entry. This helps to disambiguate identical entries written at different times or by different agents.
Because of the built-in fields and the uniqueness of each action hash, whenever you want to reference another piece of data, the most sensible choice is often an ActionHash.
EntryHash
An entry is identified by its EntryHash, which can be retrieved from the action that wrote it. Because they’re two separate pieces of data, an entry and its action are stored by different peers in the network.
More than one agent (and in fact more than one action from the same agent) can write the same entry, so entry hashes aren’t guaranteed to be unique. Sometimes this is a problem, but sometimes it’s what you want when you’re referencing data – for instance, when the content you want to refer to is more important than who authored it.
AgentPubKey
Each agent in a network is identified by their cryptographic public key, a unique number that’s mathematically related to a private number that they hold on their machine. Public-key cryptography is a little complex for this guide — it’s enough to know that a participant’s private key signs their source chain actions, and those signatures paired with their public key allow others to verify that they are the one who authored those actions.
An AgentPubKey isn’t a hash, but it’s the same length as one, and it’s unique just like a hash. So it can be used as a way of referring to an agent, like a user ID — and this is also why it’s used to choose peers in the DHT storage and retrieval algorithm.
Summary
Whereas EntryHash is used to uniquely identify, store, and efficiently retrieve an entry from the DHT, ActionHash does the same for the action that operated on it, which can provide information about the history and context of any associated entry (including what action preceded it). ActionHashes are also what enable any participant to retrieve and reconstruct the continuous sequence of actions (and any associated entries) in another agent’s source chain.
Use EntryHash when you want to link to or retrieve the actual content or data (e.g., when linking to a category in a forum application).
Use ActionHash when you want to link to or retrieve the entry content along with its authorship context (e.g., when distinguishing between two posts with identical content).
Use AgentPubKey when you want to link to an agent (such as associating a profile or icon with them) or retrieve information about their history (such as scanning their source chain for posts and comments).
You can check out the Core Concepts to dive a bit deeper into how the distributed hash table helps to not only make these entries and actions available but helps to ensure that agents haven’t gone back to try and change their own histories after the fact. But for now, let’s dive into links.
After pressing Enter, you should see:
? Should a link from the ActionHash provided in this field also be created when entries of this type are created? (y/n) ›
Press Y to accept creating a link.
Next you will see:
✔ Which entry type is this field referring to?
❯ Post
Press Enter to accept the suggested entry type Post. Then press N to decline adding another field to the entry.
You should then see a similar confirmation to when you were creating a post:
Chosen fields:
content: String, post_hash: ActionHash
? Do you want to proceed with the current entry type or restart from the beginning? ›
❯ Confirm
Modify
Restart
If the summary looks like this, press Enter. Then at the next question, use the arrow keys to deselect Update, but leave Delete selected. It should look as follows:
Which CRUD functions should be scaffolded (SPACE to select/unselect, ENTER to continue)?
Update
✔ Delete
Once that is done, press Enter to generate a delete function for the comment entry type.
You should then see:
Entry type "comment" scaffolded!
Add new collections for that entry type with:
hc scaffold collection
The scaffolding will now have both added the comment entry type, and added a bunch more very useful code to our app using the native Holochain affordance of links. Links allow us to create paths that agents can follow to find associated content. So, the scaffolding not only added a reference to the post in the comment’s entry, but it also added code such that when a comment is added, a link from the post back to the comment will also be created. If you want to see some of that code, take a look at the dnas/forum/zomes/integrity/posts/src/lib.rs file and you should see right near the top that a function has been created for validating the creation of a post_to_comments link. Similarly, other validation functions related to the deletion of those links follow after.
How links are stored and retrieved in a Holochain app
What exactly is a link? Where is it stored? How does it work? And what do they let us do that we couldn’t do otherwise?
Links enable us to build a graph of references from one piece of content to other pieces of content in a DHT and then to navigate that graph. This is important because without some sort of trail to follow, it is infeasible to just “search for all content” thanks to the address space (all possible hashes) being so large and spread out across machines that iterating through tme all could take millions of years.
By linking from known things to unknown things, we enable the efficient discovery and retrieval of related content in our hApp.
Storage: When an agent creates a link between two entries, a CreateLink action is written to their source chain. A link is so small that there’s no entry for the action. It simply contains the address of the base, the address of the target, the link type (which describes the relationship), and an optional tag which contains a small amount of application-specific information. The base and target can be any sort of DHT address — an EntryHash, an ActionHash, or an AgentPubKey. But there doesn’t actually need to be any data at that base, which is useful for referencing data that exists in another hash-based data store outside the DHT.
After storing the action in the local source chain, the agent then publishes the link to the DHT, where it goes to the peers who are responsible for storing the base address and gets attached to the address as metadata.
Lookup: To look up and retrieve links in a Holochain app, agents can perform a get_links query on a base DHT address. This operation involves asking the DHT peers responsible for that address for any link metadata of a given link type attached to it, with an optional “starts-with” query on the link tag. The peers return a list of links matching the query, which contain the addresses of the targets, and the link types and tags. The agent can then retrieve the actual target data by performing a get query on the target address, which may be an EntryHash, ActionHash, or AgentPubKey (or an empty result, in the case of data that doesn’t exist on the DHT).
For more information and examples, read the Core Concepts section on Links and Anchors.
9. Scaffold a collection
Now, let’s create a collection that can be used to retrieve all the posts. A collection creates a link type for referring to the collected entry type (similarly to how a link type was created for linking from posts to comments), but collections also create an ‘anchor’ — a small string — as the base for the link so we can find all the items in the collection by starting from the anchor’s known hash.
To create a collection, type:
hc scaffold collection
You should then see:
Collection name (snake_case, eg. "all_posts"): ›
Enter:
all_posts
and press Enter. You should then see:
? Which type of collection should be scaffolded? ›
❯ Global (get all entries of the selected entry types)
By author (get entries of the selected entry types that a given author has created)
Select Global and press Enter. You should then see:
? Which entry type should be collected? ›
❯ Post
Comment
Select Post and press Enter. You should then see:
Collection "all_posts" scaffolded!
If you want the newly scaffolded collection's component to be the entry point for its UI, import the
generated <AllPosts /> component.
These instructions tell us that if we want to include this generated UI component in the user interface of our hApp, we need to do some manual work:
- Import the component, and
- Tell the UI to display the component.
How a collection is implemented
We already explored how links make data in the DHT discoverable by connecting known DHT base addresses to unknown addresses. Essentially every address becomes an anchor point to hang a collection of links from.
But there’s one remaining problem: where do you start? When someone starts their app for the first time, the only DHT base addresses they know about are their public key, the DNA hash, and the few actions and entries on their source chain. There’s no obvious way to start discovering other people’s data yet.
This is where collections help out. A collection is just a bunch of links on a base address that’s easy to find — typically the address is hard-coded in the coordinator zome’s code as the hash of a string such as "all_posts". It’s easy to get the links, because their base address is right there in the code.
This pattern, which we call the “anchor pattern”, is so useful that it’s built right into Holochain’s SDK — integrity zomes that use it will have all the necessary entry and link types automatically defined, and coordinator zomes that use it will have functions that can retrieve anchors and the links attached to them. The scaffolded code uses this implementation behind the scenes.
The built-in implementation is actually a simplification of a more general pattern called “paths”, which is also built into the SDK. With paths, you can create trees of linked anchors, allowing you to create and query hierarchical structures. This can be used to implement categories, granular collections (for example, “all posts” → “all posts created in 2023” → “all posts created in 2023-05” → “all posts created on 2023-05-30”), and indexes for type-ahead search (for example, “all usernames” → “all usernames starting with ‘mat’” → “all usernames starting with ‘matt’”). What the SDK calls an Anchor is actually a tree with a depth of two, in which the root node is two empty bytes.
Hierarchical paths serve another useful purpose. On the DHT, where every node is tasked with storing a portion of the whole data set, some anchors could become “hot spots” — that is, they could have thousands or even millions of links attached to them. The nodes responsible for storing those links would bear a disproportionate data storage and serving burden.
The examples of granular collections and type-ahead search indexes breaks up those anchors into increasingly smaller branches, so that each leaf node in the tree — and hence each peer — only has to store a small number of links.
The scaffolding tool doesn’t have any feature for building anchors and trees beyond simple one-anchor collections, but if you’d like to know more, you can read the Core Concepts section on Links and Anchors and the SDK reference for hash_path and anchor.
Before you get started editing the UI, it’s helpful to be able to actually run the scaffolded application. That way, you can watch changes take effect in real-time as you make them. So the next section will walk you through launching the application the tooling that’s available there, and then in the section after that, we’ll begin working with the .svelte files to build the UI.
Exploring the scaffolding tool
hc scaffold has some other subcommands, plus extra arguments, beyond what we’ve explored here. To learn more, go to the scaffolding tool documentation or type
hc scaffold --help
You can also get help on any subcommand by typing (for example):
hc scaffold collection --help
10. Run your application in dev mode
Warning for Ubuntu 24.04 and later
Ubuntu Linux 24.04 introduces security policy changes that cause the following command to fail. Here’s a simple fix. In your terminal, run this command:
sudo chown root:root node_modules/electron/dist/chrome-sandbox && sudo chmod 4755 node_modules/electron/dist/chrome-sandbox
You’ll need to do this once (but only once) for every new project you scaffold. You can find out more here.
At this stage, we’ll incorporate some of the UI components that have been scaffolded by the scaffolding tool into our main application interface. Our aim here is to make all the functionality of our forum application accessible from a single, unified interface. We’ll use Svelte to accomplish this, as it is the framework that we have chosen for the UI layer of our application.
Start the forum hApp in develop mode from the command line: go to your terminal and, from the root folder (my_forum_app/), enter:
npm start
Work in the nix shell
If you are having an issue, make sure that you are still in the nix shell. If not, re-enter nix develop first, then type the above command again. And remember that you can always exit nix shell by typing exit to get back to your normal shell.
When you start the hApp with npm start, this launches Holochain in sandbox mode with two agents running that hApp, and opens two windows:
- An application window with one agent (conductor 0) running the forum hApp. This window lets us take actions as that agent (0, or Alice, if you prefer).
- Another application window with a second agent (conductor 1) running the forum hApp. This window lets us take actions as the other agent (1, or Bob).
These application windows allow us to test multiple agents in a Holochain network interacting with one another. It is all running on our one device, but the two conductors behave very much the same as separate agents on different machines would, minus network lag.
Remember that a conductor is a Holochain runtime process executing on your computer. For more details see the Application Architecture section in the Core Concepts guide.
The two application UI windows let you interact with the application and see what is working, what is not working, and how data propagates when we take particular actions. They also support hot-reloading, so you can see your UI edits immediately.
At first, each of the UI windows (conductors 0 for Alice and 1 for Bob) include instructions for you to go and examine the scaffolded UI elements by looking at the contents in the folder ui/src/<dna>/<zome>/, where <dna> and <zome> are generic placeholders for your DNA (forum) and zome (post).
11. Integrate the generated UI elements
Thus far, seven different UI components should have been generated as .svelte files in the ui/src/forum/posts/ folder. Note that for ease of development, the sandbox testing environment live-reloads the UI as you edit UI files. So don’t quit the process you started with npm start; instead, open a new terminal window. Then navigate to the root folder of your hApp (my_forum_app/) and list the files in ui/src/forum/posts/ by entering:
ls ui/src/forum/posts/
You should see seven different .svelte files, plus a types.ts file:
AllPosts.svelte CreateComment.svelte PostDetail.svelte
CommentDetail.svelte CreatePost.svelte types.ts
CommentsForPost.svelte EditPost.svelte
The next step is to edit the UI files in the text editor or integrated development environment of your choice to add scaffolded components and build a fully featured UI. To integrate all of these generated UI elements, you’ll need to add them to App.svelte file located in the ui/src/ folder, or to some other .svelte file that eventually gets included in App.svelte.
If you don’t yet have path commands for opening files in your preferred IDE, there are instructions for VSCode/VSCodium, Sublime Text and WebStorm. Going forward in this tutorial, we are going to use the code command when we mean for you to open files in your IDE, but you should substitute a different command (ex: subl, vim, emacs, etc.) for code if you are using a different editor.
Open the App.svelte file with your preferred IDE.
code ui/src/App.svelte
Your App.svelte file will have three sections:
- a script section,
- a main section containing a markup template, and
- a style section containing a stylesheet template.
Detailed breakdown of `App.svelte`
<script> section
<script lang="ts">
import { onMount } from "svelte";
import { setContext } from "svelte";
import logo from "./assets/holochainLogo.svg";
import ClientProvider from "./ClientProvider.svelte";
import { CLIENT_CONTEXT_KEY, createClientStore } from "./contexts";
const clientStore = createClientStore();
setContext(CLIENT_CONTEXT_KEY, clientStore);
let { error, loading } = $derived($clientStore);
onMount(() => {
clientStore.connect();
});
</script>
This section contains the JavaScript/TypeScript code for the component. It imports various dependencies needed to build a single-page web app:
svelteis the Svelte engine itself, and itsonMountfunction lets you register a handler to be run when the component is initialized, whilesetContextlets you pass data to be used in the rendering of the component.@holochain/clientis a client library that talks to the local Holochain service; we’re loading in some useful Holochain-related TypeScript types, followed byAppWebsocket, the client object itself../contextsdefines the ‘client context’. We won’t go into deep detail about context because it’s a Svelte thing, not a Holochain thing, but in short it’s a way of making data and functions available to child components, sort of like a semi-global variable. We’ll explain what this particular context is in a moment.
After importing dependencies, it does some initial setup. This is run when the component file is imported — in this case the component, App.svelte, is the main component for the entire application, and it’s imported into main.ts where it’s ‘mounted’ (more on mounting in a moment).
Next some variables are instantiated:
errorstores any connection error so it can be displayed in the UI.loadingkeeps track of whether the client has finished connecting to Holochain so the ‘connecting’ message can be removed.
Next, there’s an onMount handler, which is run when the component is first displayed. Again, this is a Svelte thing; in short it runs when the component first appears in the document. The handler currently does one thing: it connects to the hApp backend.
<ClientProvider> section
<ClientProvider>
<div>
<div>
<a href="https://developer.holochain.org/get-started/" target="_blank" rel="noopener noreferrer">
<img src={logo} class="logo holochain" alt="holochain logo" />
</a>
</div>
<h1>Holochain Svelte hApp</h1>
<div>
<div class="card">
{#if loading}
<p>connecting...</p>
{:else if error}
<p>{error.message}</p>
{:else}
<p>Client is connected.</p>
{/if}
</div>
<p>
Import scaffolded components into <code>src/App.svelte</code> to use
your hApp
</p>
<p class="read-the-docs">Click on the Holochain logo to learn more</p>
</div>
</div>
</ClientProvider>
This section is a template for the displayable content of the main app component. Using an {#if} block to test whether the reactive variable loading is true, this section displays a ‘loading’ message until the backend can be accessed. Once the UI is connected to the backend, it shows some boilerplate text telling you to add something meaningful to the template.
Note that, in Svelte, any time a variable used in the template changes, the template is re-rendered with the new value. This is called reactivity, and makes your life easier because you don’t have to write quite so many event handlers for changes on your data.
<style> section
<style>
.logo {
height: 15em;
padding: 1.5em;
will-change: filter;
transition: filter 300ms;
width: auto;
}
.logo:hover {
filter: drop-shadow(0 0 2em #646cffaa);
}
.logo.holochain:hover {
filter: drop-shadow(0 0 2em #61dafbaa);
}
.card {
padding: 2em;
}
.read-the-docs {
color: #888;
}
</style>
This section is a template for the CSS styles that get applied to the HTML in the <ClientProvider> section of the component. You can also use reactive variables here, and the styling will update whenever the variables change. These scaffolded styles set the component up with some basic layout to make it readable at small and large window sizes.
All Svelte components follow this general pattern. App.svelte has special status as the root component, but otherwise it’s just like any other component.
First you’ll be adding a list of posts to the app, which means the components called AllPosts.svelte needs to be imported.
At the top of the file, there is a list of scripts that are imported. Following the instructions that the scaffolding tool and the two conductor windows gave you, copy the following text and paste it into the script block of the App.svelte file, on the line below import { CLIENT_CONTEXT_KEY, createClientStore } from "./contexts";
import { CLIENT_CONTEXT_KEY, createClientStore } from "./contexts";
+import AllPosts from "./forum/posts/AllPosts.svelte";
import { CLIENT_CONTEXT_KEY, createClientStore } from "./contexts";
import AllPosts from "./forum/posts/AllPosts.svelte";
Next, edit the markup template in the <ClientProvider> section of the file, where the boilerplate content now lives. Remove the Holochain logo at the top, give it a more meaningful title, and — most importantly — replace the last two paragraphs with the <AllPosts/> component:
<ClientProvider>
<div>
- <div>
- <a href="https://developer.holochain.org/get-started/" target="_blank" rel="noopener noreferrer">
- <img src={logo} class="logo holochain" alt="holochain logo" />
- </a>
- </div>
- <h1>Holochain Svelte hApp</h1>
+ <h1>My Forum hApp</h1>
<div>
<div class="card">
{#if loading}
<p>connecting...</p>
{:else if error}
<p>{error.message}</p>
{:else}
<p>Client is connected.</p>
{/if}
</div>
- <p>
- Import scaffolded components into <code>src/App.svelte</code> to use
- your hApp
- </p>
- <p class="read-the-docs">Click on the Holochain logo to learn more</p>
+ <AllPosts/>
</div>
</div>
</ClientProvider>
<ClientProvider>
<div>
<h1>My Forum hApp</h1>
<div>
<div class="card">
{#if loading}
<p>connecting...</p>
{:else if error}
<p>{error.message}</p>
{:else}
<p>Client is connected.</p>
{/if}
</div>
<AllPosts/>
</div>
</div>
</ClientProvider>
Svelte component tags
The ClientProvider and AllPosts elements are obviously not standard HTML. In Svelte, each component has a correspondingly named custom element that will get replaced by the rendered component’s markup wherever it appears in another component’s template.
Save that file and take a look again at the two UI windows. They should both say ‘No posts found’.

Let’s fix that by adding the post creation component to the UI so we can add our first post. Import the CreatePost.svelte component by adding this line in the script section, just below the AllPosts component you previously imported:
import { CLIENT_CONTEXT_KEY, createClientStore } from "./contexts";
import AllPosts from "./forum/posts/AllPosts.svelte";
+import CreatePost from "./forum/posts/CreatePost.svelte";
import { CLIENT_CONTEXT_KEY, createClientStore } from "./contexts";
import AllPosts from "./forum/posts/AllPosts.svelte";
import CreatePost from "./forum/posts/CreatePost.svelte";
Add this new component to the <ClientProvider> block above the component you added:
<ClientProvider>
<div>
<h1>My Forum hApp</h1>
<div>
<div class="card">
{#if loading}
<p>connecting...</p>
{:else if error}
<p>{error.message}</p>
{:else}
<p>Client is connected.</p>
{/if}
</div>
+ <CreatePost/>
<AllPosts/>
</div>
</div>
</ClientProvider>
<ClientProvider>
<div>
<h1>My Forum hApp</h1>
<div>
<div class="card">
{#if loading}
<p>connecting...</p>
{:else if error}
<p>{error.message}</p>
{:else}
<p>Client is connected.</p>
{/if}
</div>
<CreatePost/>
<AllPosts/>
</div>
</div>
</ClientProvider>
Save the file and switch to one of the two conductor windows. You should now see a post form.
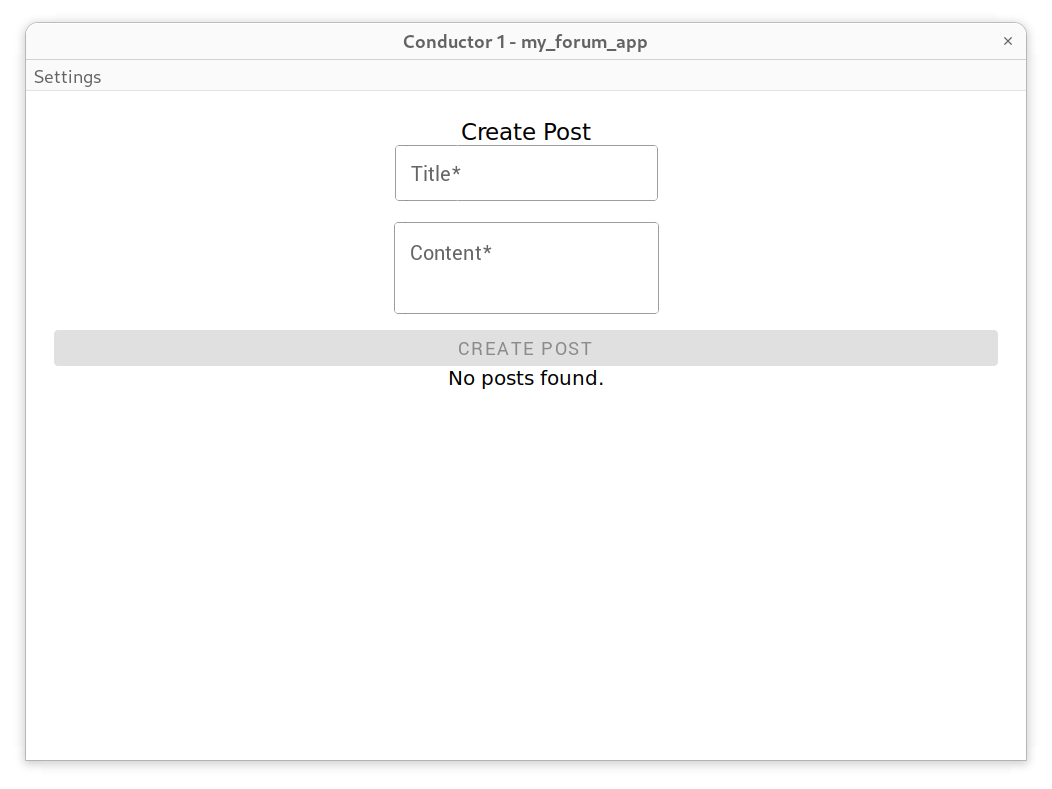
Type something into one of the two conductor windows like:
- Title:
Hi from Alice - Content:
Hello Bob!
and then press the “Create Post” button.
You’ll immediately notice that the AllPosts component has changed from saying “No posts found” to showing the newly created post.
Relationships in a source chain versus relationships in the DHT
At this point, in our DHT graph it should look like we have two different agents and then a separate floating entry and action. But we know that the new post is associated with a source chain which is associated with an agent. So why aren’t they connected on the DHT?
A source chain merely serves as a history of one agent’s attempts to manipulate the state of the graph database contained in the DHT. It’s useful to think of the DHT as a completely separate data store that doesn’t necessarily reflect agent-to-entry relationships unless you explicitly create a link type for them.
For the purpose of this hApp, we’re not interested in agent-to-posts relationships, so it’s fine that they’re not linked. But if you wanted to create a page that showed all posts by an author, that’s when you might want to scaffold that link type. hc scaffold collection will do this for you if you choose a by-author collection, and will also create a corresponding coordinator function and Svelte component.
You may also notice that only Alice’s UI showed the new post, while Bob’s didn’t. Just as with a traditional web app, database changes don’t automatically send out a notification to everyone who is interested. (Alice’s UI sees the changes because it knows how to update its own state for local changes.) You can create this functionality using a feature called signals, but let’s keep things simple for now. Right-click anywhere in Bob’s UI then choose “Reload” from the menu, and you’ll see that the changes have been copied from Alice’s app instance to Bob’s — all without a database server in the middle!
Let’s edit that post. In Alice’s UI window, click the edit link adjacent to the post content (it should look like a pencil icon). The post content will be replaced by an editing form.
Now alter the content a bit. Maybe change it from Hello Bob! to Hello World! and click “Save”.
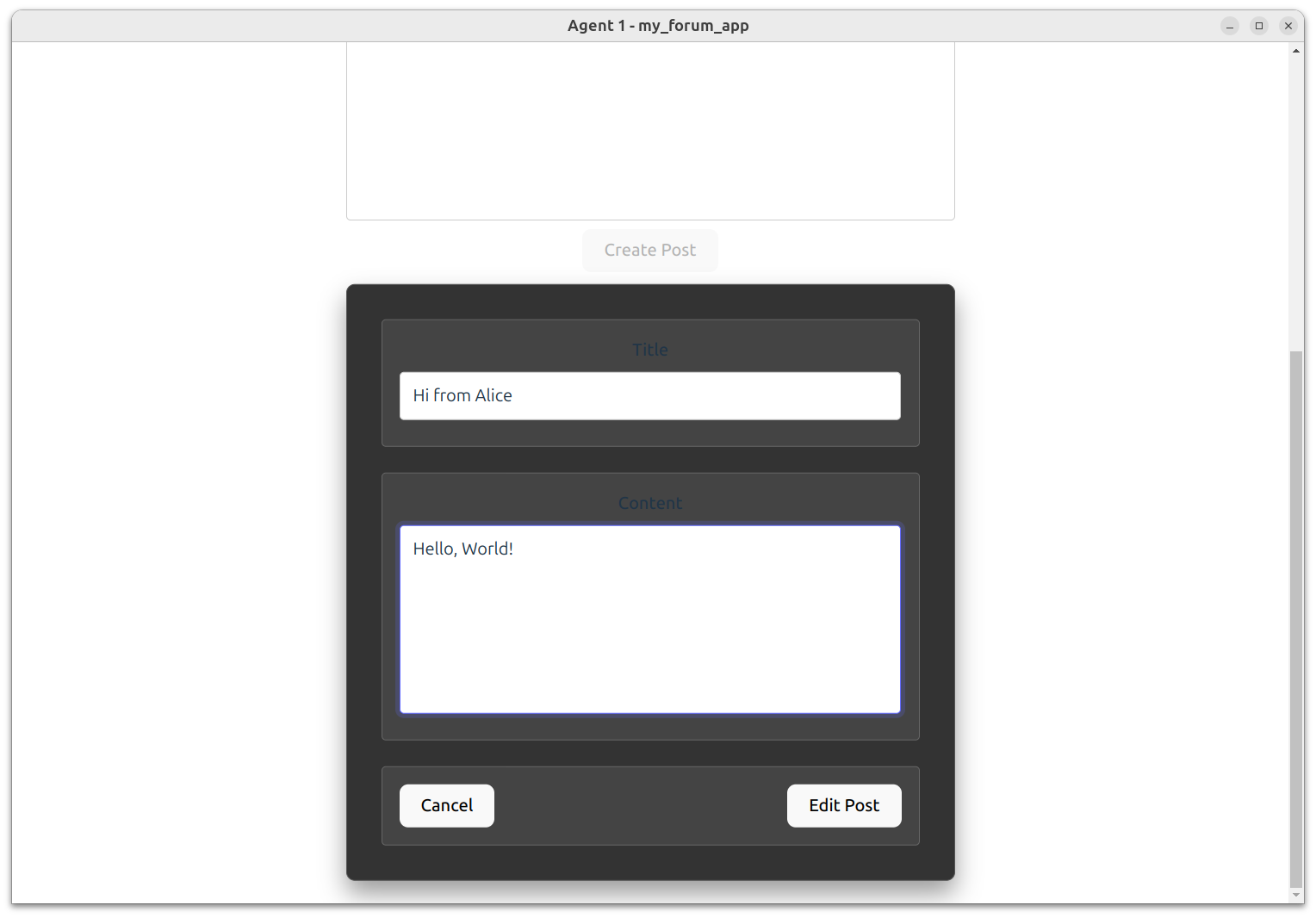
That should update the post (at least for Alice). Bob’s UI will show the updated version the next time it’s reloaded.
As explained previously, the original forum post already has a ‘link’ of sorts pointing from its action to the Update action, which can be accessed when the original is retrieved. The extra link created by the CreateLink action is optional — it merely speeds up retrieval when an action has been edited many times and has a long chain of update links, by allowing you to jump to the end of the chain. In the screenshot above, the link is highlighted in the DHT pane.
Now it’s time to add commenting to your app.
Previously, you added new components to the App.svelte component. That made sense because posts were a global data type. But comments are related to a post, so from now on you’ll be modifying the PostDetail.svelte component instead.
Open up PostDetail.svelte in your IDE:
code ui/src/forum/posts/PostDetail.svelte
Just as before, first you’ll need to import the components near the top of the file (just after the line that imports EditPost.svelte):
import EditPost from "./EditPost.svelte";
+import CreateComment from "./CreateComment.svelte";
+import CommentsForPost from "./CommentsForPost.svelte";
import type { Post } from "./types";
import EditPost from "./EditPost.svelte";
import CreateComment from "./CreateComment.svelte";
import CommentsForPost from "./CommentsForPost.svelte";
import type { Post } from "./types";
Near the end of the file, in the template block, add the components’ elements to the template. Put them both after the closing </section> tag and before the closing {/if} block.
Here, the comment components need to know what post they’re related to. The post hash is the unique ID for the post, and the comment components’ elements both expect a postHash attribute. This hash is available in the PostDetail component as a variable of the same name, so it can be passed to the comment widgets.
</section>
+ <CreateComment postHash="{postHash}"></CreateComment>
+ <CommentsForPost postHash="{postHash}"></CommentsForPost>
{/if}
</section>
<CreateComment postHash="{postHash}"></CreateComment>
<CommentsForPost postHash="{postHash}"></CommentsForPost>
{/if}
Save the file, then go back to the UI windows to see the changes. (You may have to manually reload the UI; right-click anywhere and click ‘Reload’.) Try typing in a comment or two, then deleting them. (You may need to refresh the UI windows to see the changes to the content.) The deleted comments are still there and can be accessed by code in your zomes if needed, but neither the application backend (that is, the functions defined in the coordinator zome) nor the UI have the capacity to show them.
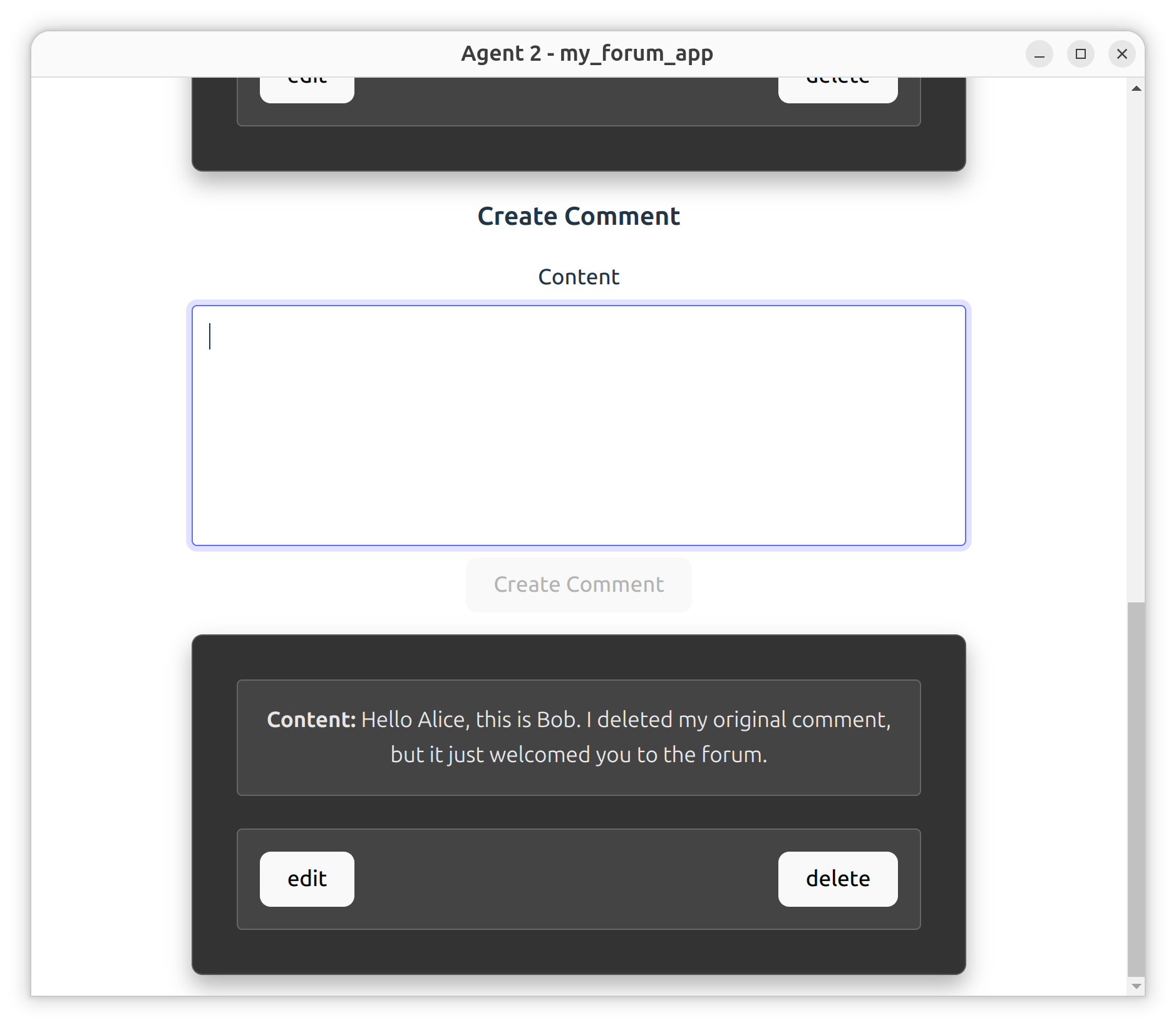
Next up
Now that you’ve built a hApp, you can learn how to package it for distribution to your users.
